#338: Multi-Agents in LangGraph
A multi-agent system is an architecture style where we split a larger task across several specialised agents instead of relying on one LLM call to do everything. Each agent can have its own role, such as planning, researching, validating, or writing the final answer. That way we can build workflows that are easier to control and to extend.
In LangGraph we can build this kind of applications with nodes that represent the agents and let the workflow guide the communication between them. This approach let us reuse most of what we already know about LangGraph while the multi-agents are in control of their subject.
To illustrate the principle, we create a little debate club where we have an optimistic agent and a pessimistic one that debate the merits of a suggested idea. At the end we go through their points and suggest the next call to action.
Preparation
As with all applications that use a LLM, we need a connect to use it:
Helper functions
We need a few helper functions to optimise our code:
parse_points()extracts the points our agents make.debate()handles the heavy lifting of sending data to the LLM and getting it back into a usable form.synthesizer()creates a summary of the debate and suggests what we should do next.route()helps us to direct the conversation to the next node.
The agents
For our example we need a pessimist and an optimist to debate our ideas. For that we create two functions and use different prompts to instruct the LLM to produce the kind of answers we are looking for:
Build the workflow
We have now everything in place to build our workflow:
Our workflow looks like this:
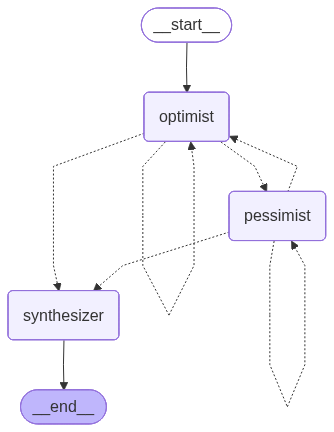
We can run our application with this main function:
Run the application
When we run our application, we will see what the optimist and the pessimist find for the topic of "Migrating a legacy monolith to a fully decentralized AI-agent architecture" and how our synthesizer consolidates their points into a summary:
uv run .\multi_agent_debate.py
--- DEBATE --- Migrating a legacy monolith to a fully decentralized AI-agent
architecture.
[optimist] turn=1
[+] Every micro‑service becomes an autonomous AI agent that learns and scales
on demand, turning the stack into a self‑optimizing ecosystem.
[+] Decentralization eliminates single‑point failures; uptime jumps from 99 %
to near‑continuous availability, unlocking new revenue streams for always‑on
services.
[+] Open‑source agents foster rapid innovation—developers worldwide can plug
in cutting‑edge models, turning the platform into a global AI marketplace
that grows exponentially with community contributions.
[route] turn=1 -> pessimist
[pessimist] turn=2
[-] The “self‑optimizing” claim ignores that each agent will need constant
retraining data pipelines and monitoring; without a central governance layer,
drift and malicious exploitation become inevitable, turning the system into
a maintenance nightmare.
[-] Decentralization may reduce single‑point failures but introduces consensus
latency, network partition risks, and higher bandwidth costs—downtime can
actually increase during peak loads or when nodes disagree on state.
[-] Relying on open‑source contributions assumes a steady influx of
high‑quality models; in reality the ecosystem will fragment into incompatible
forks, leading to security holes, duplicated effort, and an unmanageable patch
cycle.
[route] turn=2 -> optimist
[optimist] turn=3
[+] Each agent’s learning loop can be automated with federated training and
continuous validation, turning the “maintenance nightmare” into a self‑healing
system that reduces human toil over time.
[+] Decentralized consensus protocols are now engineered for sub‑second
finality; combined with edge caching, they deliver lower latency than
monoliths while still protecting against single‑point failures.
[+] A thriving open‑source ecosystem fuels rapid iteration—community vetting
and modular plug‑ins create a living marketplace where the best models surface
naturally, eliminating fragmentation through shared standards and incentive
layers.
[route] turn=3 -> pessimist
[pessimist] turn=4
[-] The “self‑healing” claim ignores that federated learning introduces
catastrophic model drift; without a central audit trail, malicious actors
can poison data and silently corrupt every agent.
[-] Sub‑second consensus is theoretical; real‑world networks suffer from
latency spikes, packet loss, and Byzantine faults that will still cause
outages far worse than the monolith’s single point of failure.
[-] Open‑source hype masks the reality that most contributors lack rigorous
security vetting; fragmented forks proliferate, creating a patchwork of
incompatible, vulnerable agents that explode maintenance costs rather than
reduce them.
[route] turn=4 -> synthesizer
[synthesizer] picking top 2 opportunities + top 2 risks + a verdict from
12 points
--- SUMMARY ---
[+] Every micro‑service becomes an autonomous AI agent that learns and scales
on demand, turning the stack into a self‑optimizing ecosystem.
[+] Decentralization eliminates single‑point failures; uptime jumps from 99 %
to near‑continuous availability, unlocking new revenue streams for always‑on
services.
[-] The “self‑optimizing” claim ignores that each agent will need constant
retraining data pipelines and monitoring; without a central governance layer,
drift and malicious exploitation become inevitable, turning the system into a
maintenance nightmare.
[-] Decentralization may reduce single‑point failures but introduces consensus
latency, network partition risks, and higher bandwidth costs—downtime can
actually increase during peak loads or when nodes disagree on state.
[>] REVISIT: The potential for catastrophic drift and operational complexity
outweighs the projected uptime gains until robust governance and monitoring
are established.
--- /SUMMARY ---
In this run the verdict is to go back to the drawing board. If we increase the temperature of the LLM we will get a wider range of answers and that may result in a good to go decision. If you want to debate a different question, you can change the main() function and see how the results change.
Next
Multi-agents in LangGraph do not look much different from regular workflows. In both cases we can put the needed logic into independent nodes and use routing to define where the workflow should go next.
Next week we take a look at Obsidian and figure out how we can use Python to interact with.