#249: Migrate from WordPress to Markdown
With Material for MkDocs I found a valid alternative for WordPress. There is only one large obstacle left: How do we get the blog posts from WordPress to Markdown?
Export the posts
WordPress offers us a way to export our posts. To see the option, we need to log-in with an administrator account. In the Tools section we find the Export feature that allows us to export main part of our blog posts:
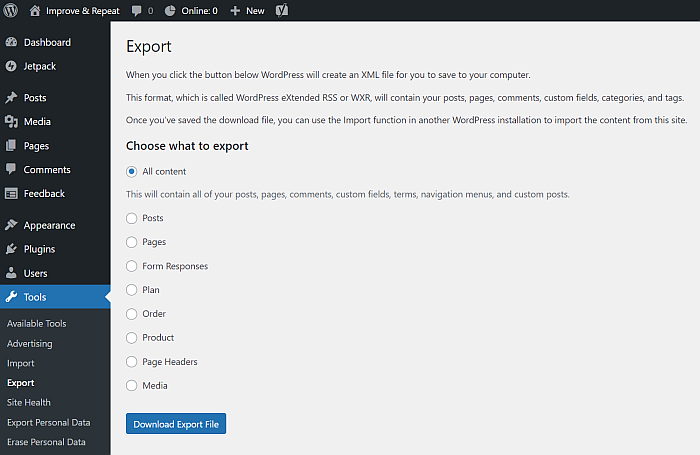
This WordPress eXtended RSS file contains all our posts, but not the media files. We will fetch them in the next step.
Converter the posts
As so often, there are many tools that claim to convert your WordPress posts to Markdown. I had to test a few until I found wordpress-export-to-markdown that did the whole job.
If you do not have a full Node.js environment, you do not need to install it. Instead, we can use this docker-compose.yaml file to create a dev container:
Crete the folder data next to the YAML file and put the WordPress export file into that new folder.
We can start the container with this command:
This will fetch the image, creates a container with Node.js for us and makes our exported WordPress file accessible inside the container. We can now connect to the container and run this command to convert our blog posts to Markdown:
After we answered a few questions on how we want to export our posts, the tool starts its work. It may take a few minutes, depending on how many images it needs to download. When it is done, we should have a structure like this one:
Improve with a script
While we now have Markdown files, they do not match everything MkDocs expects. We can fix that and optimise a few things along the way.
I want to use a different folder structure, that puts the images next to the Markdown files and renames the index.md file to something I know what is inside. This should give us a structure like this:
Inside the Markdown file, we can fix these points:
- Change the date from a string to a date object and add the time of the publication
- Remove Python Friday from the titles
- Set a language for the code samples
- Turn the links to Python Friday posts into relative links
- Replace the recuring reference to the series with a
<!-- more -->tag - Fix the links to the images that are no longer in an image folder
To get all those changes done, I wrote this little script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 | |
When we point the script to the output folder of our converter tool, it goes through the posts, makes all the changes and puts them into the desired folder structure.
Load into MkDocs
We can take the year folders from our output and add them to our docs/posts folder of our MkDocs blog. We can run the preview feature of MkDocs, and it will tell us if there is a problem with our converted posts:
It took me a few iterations to get everything right. But thanks to the Python script, it did not cost much time to retry the transformation.
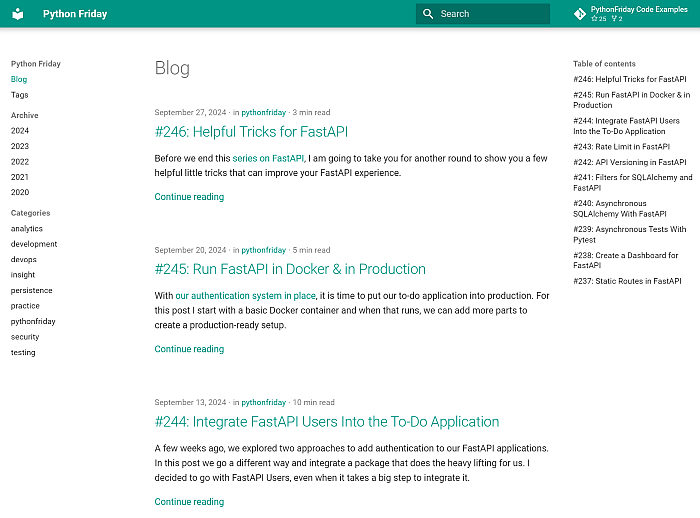
Things to fix by hand
The transformation script did a great job and fixed most problems. However, some points require a manual change. The most notable would be the highlighted lines in the code samples and the improvement of the categories and tags. That cannot be automated and takes time.
Next
With this approach we got our HTML formatted blog posts out of WordPress and into the Markdown flavour we need for MkDocs. There are a few additional tasks we need to take care of, but before we tackle them, we celebrate the 250th post of Python Friday.